特性
这是 LightGBM 工作原理的概念性概述[1]。我们假设您熟悉决策树 boosting 算法,以便将重点放在 LightGBM 与其他 boosting 包可能不同的方面。有关详细算法,请参阅引文或源代码。
速度和内存使用优化
许多 boosting 工具使用基于预排序的算法[2, 3](例如 xgboost 中的默认算法)进行决策树学习。这是一个简单的解决方案,但不容易优化。
LightGBM 使用基于直方图的算法[4, 5, 6],将连续特征(属性)值分桶到离散的 bin 中。这加快了训练速度并减少了内存使用。基于直方图的算法的优点包括以下几点
减少计算每次分裂增益的成本
基于预排序的算法的时间复杂度为
O(#data)计算直方图的时间复杂度为
O(#data),但这只涉及快速求和操作。直方图构建完成后,基于直方图的算法的时间复杂度为O(#bins),而#bins远小于#data。
使用直方图相减进一步加速
要在二叉树中获取一个叶子的直方图,可以使用其父节点与其兄弟节点的直方图相减
因此,它只需要为其中一个叶子(其数据量
#data小于其兄弟节点)构建直方图。然后,通过直方图相减可以以很小的成本(O(#bins))获得其兄弟节点的直方图
减少内存使用
将连续值替换为离散的 bin。如果
#bins较小,可以使用小数据类型,例如 uint8_t,来存储训练数据无需存储用于预排序特征值的额外信息
减少分布式学习的通信成本
稀疏优化
只需
O(2 * #non_zero_data)即可构建稀疏特征的直方图
精度优化
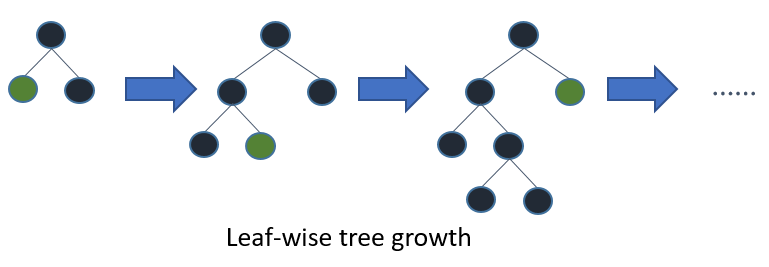
逐叶(最优优先)树生长
大多数决策树学习算法按层(深度)生长树,如下图所示
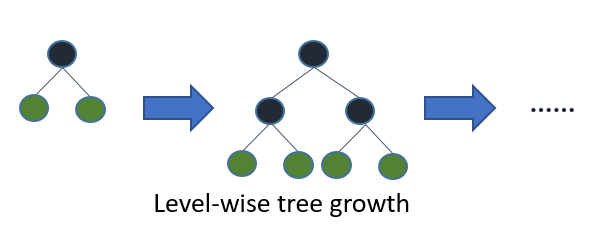
LightGBM 按叶子(最优优先)生长树[7]。它会选择 delta loss 最大的叶子进行生长。在叶子数量 #leaf 固定时,逐叶算法通常比按层算法获得更低的损失。
当数据量 #data 较小时,逐叶生长可能导致过拟合,因此 LightGBM 包含 max_depth 参数来限制树的深度。但是,即使指定了 max_depth,树仍然会按叶子生长。
类别特征的最优分裂
通常使用独热编码表示类别特征,但这种方法对于树学习器来说不是最优的。特别是对于高基数类别特征,基于独热特征构建的树往往不平衡,需要非常深才能达到良好的精度。
代替独热编码,最优的解决方案是将类别特征的类别划分成 2 个子集进行分裂。如果特征有 k 个类别,则有 2^(k-1) - 1 种可能的划分。但对于回归树,存在一种高效的解决方案[8]。它只需要大约 O(k * log(k)) 的时间来找到最优划分。
基本思想是在每次分裂时根据训练目标对类别进行排序。更具体地说,LightGBM 根据累积值(sum_gradient / sum_hessian)对直方图(针对类别特征)进行排序,然后在排序后的直方图上找到最优分裂点。
网络通信优化
在 LightGBM 的分布式学习中,只需要使用一些集合通信算法,例如“All reduce”、“All gather”和“Reduce scatter”。LightGBM 实现了最先进的算法[9]。这些集合通信算法可以提供比点对点通信更好的性能。
分布式学习优化
LightGBM 提供以下分布式学习算法。
特征并行
传统算法
特征并行旨在并行化决策树中的“寻找最优分裂”。传统特征并行的过程是
垂直划分数据(不同的机器拥有不同的特征集)。
工作节点在本地特征集上寻找本地最优分裂点 {特征,阈值}。
工作节点之间相互通信本地最优分裂点,并找到全局最优分裂点。
拥有全局最优分裂点的工作节点执行分裂,然后将数据的分裂结果发送给其他工作节点。
其他工作节点根据收到的数据进行分裂。
传统特征并行的缺点
存在计算开销,因为它无法加速“分裂”,“分裂”的时间复杂度是
O(#data)。因此,当数据量#data较大时,特征并行无法很好地加速。需要通信分裂结果,这大约花费
O(#data / 8)的开销(一个数据点需要一位)。
LightGBM 中的特征并行
由于当数据量 #data 较大时特征并行无法很好地加速,我们做了一个小改动:不是垂直划分数据,而是每个工作节点都持有完整的数据。因此,LightGBM 不需要通信数据的分裂结果,因为每个工作节点都知道如何分裂数据。而且 #data 不会更大,所以在每台机器中持有完整数据是合理的。
LightGBM 中的特征并行的过程
工作节点在本地特征集上寻找本地最优分裂点 {特征,阈值}。
工作节点之间相互通信本地最优分裂点,并找到全局最优分裂点。
执行最优分裂。
然而,当数据量 #data 较大时,这个特征并行算法在“分裂”时仍然存在计算开销。因此,当数据量 #data 较大时,最好使用数据并行。
数据并行
传统算法
数据并行旨在并行化整个决策树学习过程。数据并行的过程是
水平划分数据。
工作节点使用本地数据构建本地直方图。
合并所有本地直方图以得到全局直方图。
从合并的全局直方图找到最优分裂点,然后执行分裂。
传统数据并行的缺点
高通信成本。如果使用点对点通信算法,一台机器的通信成本大约为
O(#machine * #feature * #bin)。如果使用集合通信算法(例如“All Reduce”),通信成本大约为O(2 * #feature * #bin)(请查阅 [9] 中 4.5 章关于“All Reduce”的成本)。
LightGBM 中的数据并行
我们降低了 LightGBM 中数据并行的通信成本
LightGBM 没有使用“合并所有本地直方图以得到全局直方图”,而是使用“Reduce Scatter”为不同的工作节点合并不同(不重叠)特征的直方图。然后工作节点在本地合并的直方图上找到本地最优分裂点,并同步全局最优分裂点。
如前所述,LightGBM 使用直方图相减来加速训练。基于此,我们只需通信一个叶子的直方图,并通过相减获得其兄弟节点的直方图。
综合来看,LightGBM 中数据并行的时间复杂度为 O(0.5 * #feature * #bin)。
投票并行
GPU 支持
感谢 @huanzhang12 贡献此特性。请阅读 [11] 获取更多详细信息。
应用和评估指标
LightGBM 支持以下应用
回归,目标函数是 L2 loss
二分类,目标函数是 logloss
多分类
交叉熵,目标函数是 logloss 并支持在非二分类标签上进行训练
LambdaRank,目标函数是带有 NDCG 的 LambdaRank
LightGBM 支持以下评估指标
L1 loss
L2 loss
Log loss
分类错误率
AUC
NDCG
MAP
多分类 log loss
多分类错误率
AUC-mu
(v3.0.0 新增)平均精度
(v3.1.0 新增)Fair
Huber
泊松
分位数
MAPE
Kullback-Leibler
Gamma
Tweedie
有关更多详细信息,请参阅参数。
其他特性
逐叶生长树时限制树的
max_depthL1/L2 正则化
Bagging
列(特征)子抽样
使用输入的 GBDT 模型继续训练
使用输入的 score 文件继续训练
加权训练
训练期间输出验证评估指标
多个验证数据集
多个评估指标
提前停止(训练和预测均可)
预测叶子索引
有关更多详细信息,请参阅参数。
参考文献
[1] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu. “LightGBM: A Highly Efficient Gradient Boosting Decision Tree.” Advances in Neural Information Processing Systems 30 (NIPS 2017), pp. 3149-3157.
[2] Mehta, Manish, Rakesh Agrawal, and Jorma Rissanen. “SLIQ: A fast scalable classifier for data mining.” International Conference on Extending Database Technology. Springer Berlin Heidelberg, 1996.
[3] Shafer, John, Rakesh Agrawal, and Manish Mehta. “SPRINT: A scalable parallel classifier for data mining.” Proc. 1996 Int. Conf. Very Large Data Bases. 1996.
[4] Ranka, Sanjay, and V. Singh. “CLOUDS: A decision tree classifier for large datasets.” Proceedings of the 4th Knowledge Discovery and Data Mining Conference. 1998.
[5] Machado, F. P. “Communication and memory efficient parallel decision tree construction.” (2003).
[6] Li, Ping, Qiang Wu, and Christopher J. Burges. “Mcrank: Learning to rank using multiple classification and gradient boosting.” Advances in Neural Information Processing Systems 20 (NIPS 2007).
[7] Shi, Haijian. “Best-first decision tree learning.” Diss. The University of Waikato, 2007.
[8] Walter D. Fisher. “On Grouping for Maximum Homogeneity.” Journal of the American Statistical Association. Vol. 53, No. 284 (Dec., 1958), pp. 789-798.
[9] Thakur, Rajeev, Rolf Rabenseifner, and William Gropp. “Optimization of collective communication operations in MPICH.” International Journal of High Performance Computing Applications 19.1 (2005), pp. 49-66.
[10] Qi Meng, Guolin Ke, Taifeng Wang, Wei Chen, Qiwei Ye, Zhi-Ming Ma, Tie-Yan Liu. “A Communication-Efficient Parallel Algorithm for Decision Tree.” Advances in Neural Information Processing Systems 29 (NIPS 2016), pp. 1279-1287.
[11] Huan Zhang, Si Si and Cho-Jui Hsieh. “GPU Acceleration for Large-scale Tree Boosting.” SysML Conference, 2018.