GPU调优指南和性能比较
工作原理?
在LightGBM中,训练阶段的主要计算开销在于构建特征直方图。我们使用高效的GPU算法来加速这一过程。实现高度模块化,适用于所有学习任务(分类、排序、回归等)。GPU加速也适用于分布式学习设置。GPU算法实现基于OpenCL,可与多种GPU兼容。
支持的硬件
我们支持AMD Graphics Core Next (GCN) 架构以及NVIDIA Maxwell和Pascal架构。大多数2012年之后发布的AMD GPU和2014年之后发布的NVIDIA GPU都应该支持。我们已经在以下GPU上测试了GPU实现
AMD RX 480,使用AMDGPU-pro驱动 16.60,系统为Ubuntu 16.10
AMD R9 280X (又名 Radeon HD 7970),使用fglrx驱动 15.302.2301,系统为Ubuntu 16.10
NVIDIA GTX 1080,使用驱动 375.39 和 CUDA 8.0,系统为Ubuntu 16.10
NVIDIA Titan X (Pascal),使用驱动 367.48 和 CUDA 8.0,系统为Ubuntu 16.04
NVIDIA Tesla M40,使用驱动 375.39 和 CUDA 7.5,系统为Ubuntu 16.04
不推荐使用以下硬件
NVIDIA Kepler(K80, K40, K20,大多数 GeForce GTX 700 系列 GPU)或更早的 NVIDIA GPU。它们不支持本地内存空间中的硬件原子操作,因此直方图构建会很慢。
基于AMD VLIW4的GPU,包括 Radeon HD 6xxx 系列和更早的 GPU。这些 GPU 已停产多年,现在很少见了。
如何在GPU上获得良好的加速效果
您可以运行我们已验证能获得良好加速效果的一些数据集(包括 Higgs, epsilon, Bosch 等),以确保您的设置正确。如果您有多块 GPU,请确保设置
gpu_platform_id和gpu_device_id来使用所需的 GPU。此外,请确保您的系统处于空闲状态(尤其在使用共享计算机时),以便获得准确的性能测量结果。GPU 最适合处理大规模和稠密数据集。如果数据集太小,在 GPU 上计算效率不高,因为数据传输开销可能很大。如果您有类别特征,请使用
categorical_column选项直接将它们输入到 LightGBM;不要将它们转换为独热(one-hot)变量。为了在 GPU 上获得良好的加速效果,建议使用较小的 bin 数量。推荐设置
max_bin=63,因为它通常不会显著影响大型数据集上的训练精度,但 GPU 训练会比使用默认的 bin 大小 255 快得多。对于某些数据集,甚至使用 15 个 bin 就足够了 (max_bin=15);使用 15 个 bin 可以最大化 GPU 性能。务必检查运行日志,验证是否使用了所需的 bin 数量。如果可能,尝试使用单精度训练 (
gpu_use_dp=false),因为大多数 GPU(尤其是 NVIDIA 消费级 GPU)的双精度性能较差。
性能比较
我们在以下数据集上评估了 GPU 加速的训练性能
数据集 |
任务 |
链接 |
#样本数 |
#特征数 |
注释 |
|---|---|---|---|---|---|
Higgs |
二分类 |
10,500,000 |
28 |
使用最后500,000个样本作为测试集 |
|
Epsilon |
二分类 |
400,000 |
2,000 |
使用提供的测试集 |
|
Bosch |
二分类 |
1,000,000 |
968 |
使用提供的测试集 |
|
Yahoo LTR |
排序学习 |
473,134 |
700 |
使用 set1.train 作为训练集,set1.test 作为测试集 |
|
MS LTR |
排序学习 |
2,270,296 |
137 |
使用 {S1,S2,S3} 作为训练集,{S5} 作为测试集 |
|
Expo |
二分类(类别型特征) |
11,000,000 |
700 |
使用最后1,000,000个样本作为测试集 |
我们使用以下硬件评估了 LightGBM GPU 训练的性能。我们的 CPU 参考平台是一台配备 28 核的高端双路 Haswell-EP Xeon 服务器;GPU 包括一块入门级 GPU (RX 480) 和一块主流级 GPU (GTX 1080),安装在同一台服务器上。值得一提的是,所使用的 GPU 并非市面上最好的 GPU;如果您使用更好的 GPU(如 AMD RX 580, NVIDIA GTX 1080 Ti, Titan X Pascal, Titan Xp, Tesla P100 等),您可能会获得更好的加速效果。
硬件 |
峰值 FLOPS |
峰值内存带宽 |
成本 (建议零售价) |
|---|---|---|---|
AMD Radeon RX 480 |
5,161 GFLOPS |
256 GB/s |
$199 |
NVIDIA GTX 1080 |
8,228 GFLOPS |
320 GB/s |
$499 |
2x Xeon E5-2683v3 (28 核) |
1,792 GFLOPS |
133 GB/s |
$3,692 |
在 CPU 上进行基准测试时,我们只使用了 CPU 的 28 个物理核心,没有使用超线程核心,因为我们发现使用太多线程反而会降低性能。下表显示了我们使用的训练配置
max_bin = 63
num_leaves = 255
num_iterations = 500
learning_rate = 0.1
tree_learner = serial
task = train
is_training_metric = false
min_data_in_leaf = 1
min_sum_hessian_in_leaf = 100
ndcg_eval_at = 1,3,5,10
device = gpu
gpu_platform_id = 0
gpu_device_id = 0
num_thread = 28
我们使用了上面显示的配置,但 Bosch 数据集除外,我们使用了较小的 learning_rate=0.015 并设置了 min_sum_hessian_in_leaf=5。对于所有 GPU 训练,我们改变了最大 bin 数量(255、63 和 15)。GPU 实现来自于 LightGBM 的 commit 0bb4a82,当时 GPU 支持刚刚合并进来。
下表列出了 CPU 和 GPU 学习器在 500 次迭代后在测试集上可以达到的精度。尽管使用了单精度算术,GPU 在相同 bin 数量下可以达到与 CPU 相似的精度水平。对于大多数数据集,使用 63 个 bin 就足够了。
CPU 255 bins |
CPU 63 bins |
CPU 15 bins |
GPU 255 bins |
GPU 63 bins |
GPU 15 bins |
|
|---|---|---|---|---|---|---|
Higgs AUC |
0.845612 |
0.845239 |
0.841066 |
0.845612 |
0.845209 |
0.840748 |
Epsilon AUC |
0.950243 |
0.949952 |
0.948365 |
0.950057 |
0.949876 |
0.948365 |
Yahoo-LTR NDCG1 |
0.730824 |
0.730165 |
0.729647 |
0.730936 |
0.732257 |
0.73114 |
Yahoo-LTR NDCG3 |
0.738687 |
0.737243 |
0.736445 |
0.73698 |
0.739474 |
0.735868 |
Yahoo-LTR NDCG5 |
0.756609 |
0.755729 |
0.754607 |
0.756206 |
0.757007 |
0.754203 |
Yahoo-LTR NDCG10 |
0.79655 |
0.795827 |
0.795273 |
0.795894 |
0.797302 |
0.795584 |
Expo AUC |
0.776217 |
0.771566 |
0.743329 |
0.776285 |
0.77098 |
0.744078 |
MS-LTR NDCG1 |
0.521265 |
0.521392 |
0.518653 |
0.521789 |
0.522163 |
0.516388 |
MS-LTR NDCG3 |
0.503153 |
0.505753 |
0.501697 |
0.503886 |
0.504089 |
0.501691 |
MS-LTR NDCG5 |
0.509236 |
0.510391 |
0.507193 |
0.509861 |
0.510095 |
0.50663 |
MS-LTR NDCG10 |
0.527835 |
0.527304 |
0.524603 |
0.528009 |
0.527059 |
0.524722 |
Bosch AUC |
0.718115 |
0.721791 |
0.716677 |
0.717184 |
0.724761 |
0.717005 |
我们记录了 500 次迭代后的实际运行时间(wall clock time),如下图所示
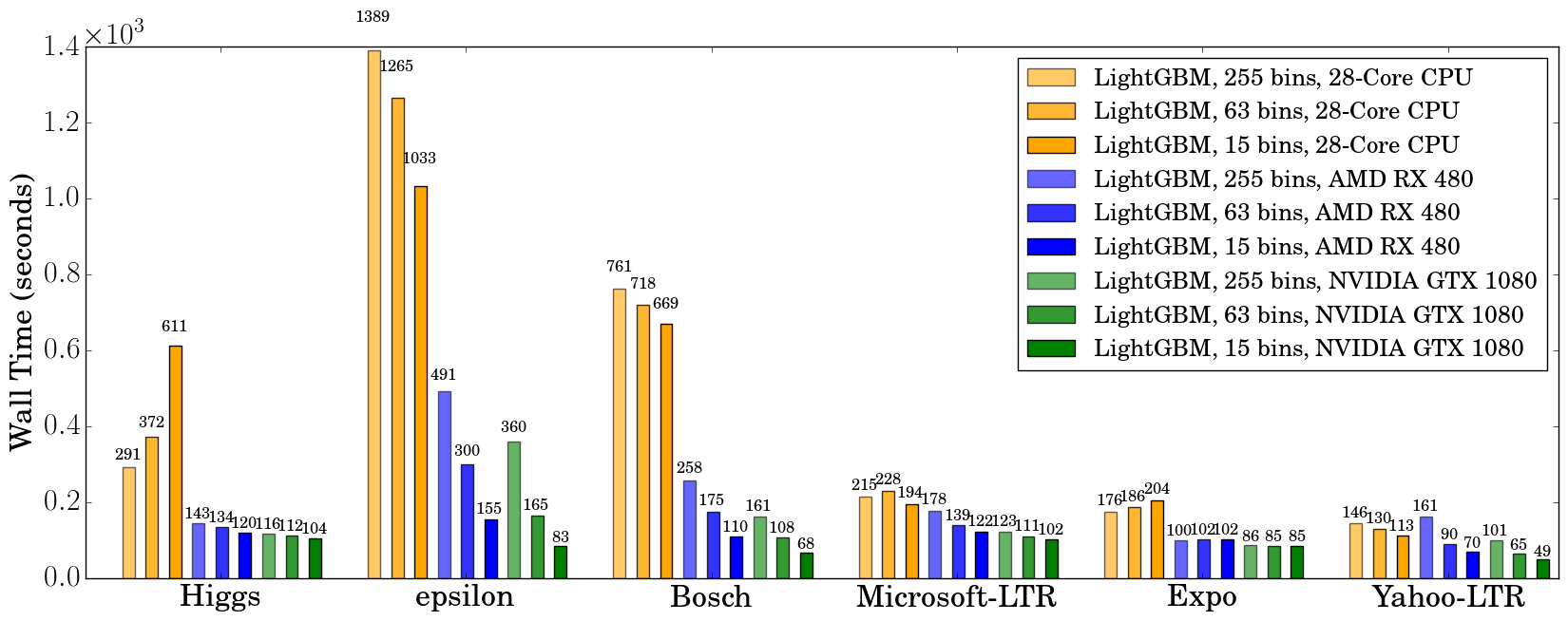
使用 GPU 时,建议使用 63 个 bin 而不是 255 个 bin,因为这可以在不显著影响精度的情况下显著加速训练。在 CPU 上,使用较小的 bin 数量只能略微提高性能,有时甚至会减慢训练速度,例如在 Higgs 数据集上(我们可以在两台不同机器上重现相同的减速,使用不同的 GCC 版本)。我们发现 GPU 在 Higgs 和 Epsilon 等大型和稠密数据集上可以实现显著的加速。即使在更小、更稀疏的数据集上,一块入门级 GPU 仍然可以与 28 核 Haswell 服务器竞争并更快。
内存使用情况
下表显示了使用 63 个 bin 进行训练时 nvidia-smi 报告的 GPU 内存使用情况。我们可以看到,即使是最大的数据集也仅使用了大约 1 GB 的 GPU 内存,这表明我们的 GPU 实现可以扩展到比 Bosch 或 Epsilon 大 10 倍以上的巨大数据集。此外,我们可以观察到,通常数据集越大(使用更多 GPU 内存,如 Epsilon 或 Bosch),加速效果越好,因为当数据集较小时,调用 GPU 函数的开销会变得很大。
数据集 |
Higgs |
Epsilon |
Bosch |
MS-LTR |
Expo |
Yahoo-LTR |
|---|---|---|---|---|---|---|
GPU 内存使用 (MB) |
611 |
901 |
1067 |
413 |
405 |
291 |
延伸阅读
您可以在以下文章中找到有关 GPU 算法和基准测试的更多详细信息
Huan Zhang, Si Si 和 Cho-Jui Hsieh。GPU Acceleration for Large-scale Tree Boosting。SysML 会议,2018年。